大話 LLM 奇幻世界

以下會談論到 LLM 這個不是非常新,但也是在兩三年竄起的 AI 應用。一切的引爆點是 Open AI 發表了 ChatGPT 3 時開始的,因為 ChatGPT 3 的內建已訓練的參數已經達到 1750 億個,相比之下已經比 ChatGPT 1 多了 1495 倍。那為什麼 ChatGPT 3 參數高達 1750 億會這麼重要呢?

我們拿人類來作比喻,一個5歲小孩的詞彙量和知識量如果跟一位清華大學生來作對比就很清楚了。我們詢問他們一個問題:「為什麼會下雨?」,以一個正常的5歲小孩並不知道這種自然科學的知識,甚至他還不會跟你說不知道,會以他幻想的原因來回覆你。(瞎掰)
以這個例子就能清楚的表示,LLM的參數多寡是多麼重要,因為參數夠多,這些參數在語言模型中才能有更多的關聯,也才能辦法進行推理。
等等!剛剛說的5歲小孩回答問題可能會幻想瞎掰來回答,那 AI LLM 也會嗎?的確是會這樣,當語言模型裡能用的參數不夠多,或者沒有經過好的調整(訓練)時就會產生幻想。
那 ChatGPT 3 已經有 1750 億個參數,這麼多參數應該不會幻想了吧!?當然不是,清華大學生也不會什麼都懂,年紀多大都多少會瞎掰對吧!(經過一兩年的進化目前各大 LLM 已經都累積千億甚至兆級的參數數)
在 LLM 中,參數可以被視為 LLM 的訓練成果,它們構成了模型的知識基礎和判斷邏輯,使得 LLM 能夠對多樣化的語言輸入做出相應的理解與回應。甚至到 ChatGPT 4 後進展到多模態大模型 (圖片、聲音、影片)。
下面我們來了解一些跟LLM有關的內容
♦ Embedding 嵌入 ♦
要提到 Embedding 之前要先知道儲存在 LLM 裡面的資料庫並不是一般的關聯式資料庫,也不是像 MongoDB 這種大數據資料庫,而是一種向量資料庫,向量資料庫裡面所存放的資料不會是一筆一筆的,而是比較是空間式的。在這個空間裡資料元跟資料元分別儲存,而語義資訊比較相近的會在這個向量空間位置也比較近。例如 Banana 跟 Apple 都是水果,語義相近。Dog 跟 Cat 都是寵物,語義相近。
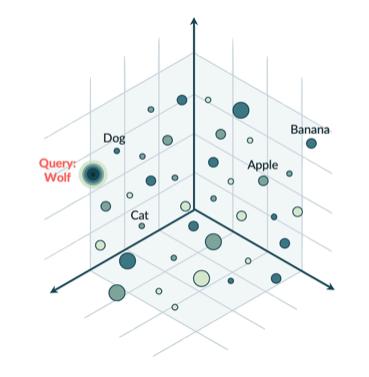
而 Embedding 就是將單詞、句子或更大的文字片段嵌入到向量空間的技術。
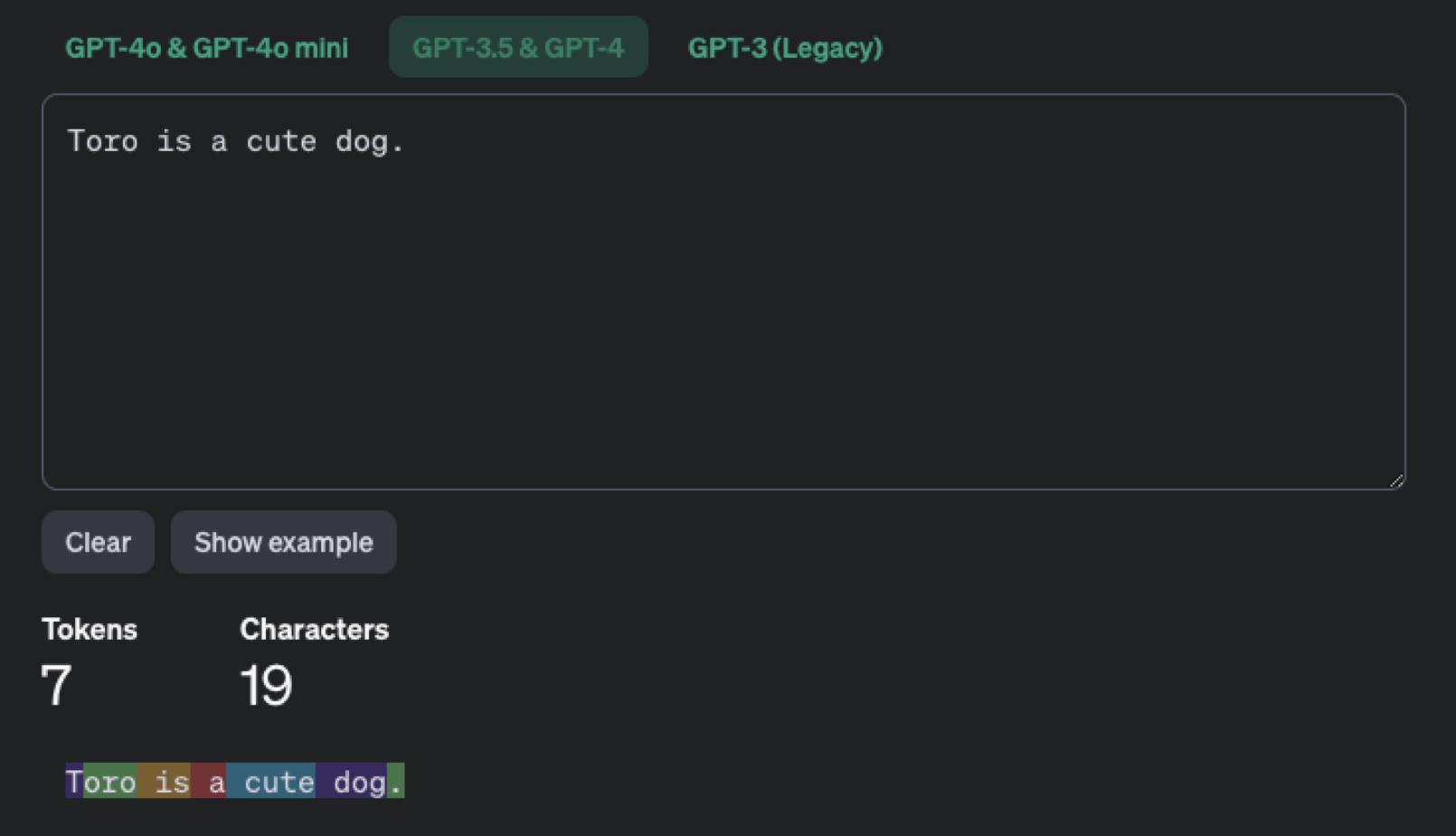
例如:Toro is a cute dog.
對於完全不懂英文的人,看到這句話是不可能知道意義的。
但透過 Embedding 技術會將句子作拆解成 q1 = Toro, q2=is, q3=a, q4=cute, q5=dog, q6=. (最後符號也算)
介由這樣的拆解後嵌入到向量空間的資料庫中,再通過模型訓練就能知道 cute 跟 dog 的關係,慢慢也就會學到狗狗是可愛的。
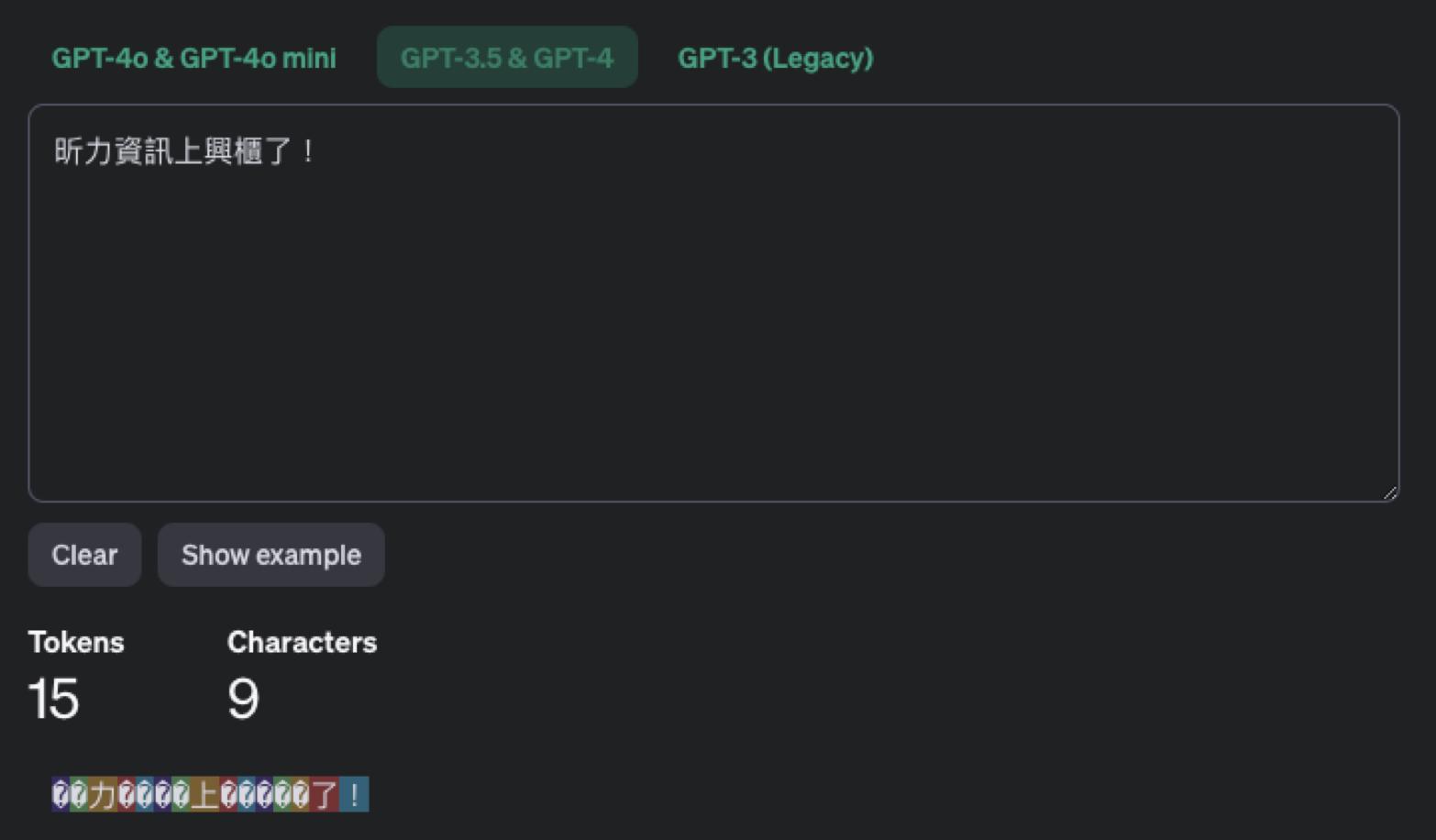
而這樣的拆解方式就成了 LLM 的計費方式,通常 LLM 是以 Token 作計費,一個單字為一個 Token,中文則跟英文不一樣,比較會以單個中文字 2 個 Token 作計算。下面兩張圖就能清楚看到在 ChatGPT 3.5 時是如何計算 Token 數的。
如此就可得知,如果讓 LLM 處理的文字量越多,則費用就會越高。
LLM 優化工程主要方法由簡易到複雜包含:常見到的有三種,分別是 Prompt、RAG、Fine-Tune。
各大科技巨擘所擁有的 LLM 動輒都具備了數千億、甚至上兆個參數。因此他們必須耗費大量的電力和算力,以及輸入海量的數據資料,才能夠完成各自LLM的學習訓練,而所謂的學習訓練,其實就是一個「參數調整」的過程。
♦ Prompt 提示工程 ♦
談到 Prompt 初學者可能開始感到恐懼,專有名詞真不少,但其實都是很人性化的,且很多都是人類本身就已經在現實生活上作的。其實 Prompt 在生活上就是懂得問問題,懂得怎麼把話說清楚。
『 什麼?它不是 AI 嗎?我以為都是很聰明自動化的!』
當然不是了,當今的 AI 就跟人類一樣,當隨意詢問對方一個問題,而沒有把問題陳述清楚時,對方可能會答非所問對吧?又者,如果在交待對方要作些什麼任務時,如果沒有把任務交待清楚,對方可能最後完成工作不是你想要的結果。
以上說的其實就是 Prompt 了。所以在跟 LLM 溝通時,想要得到較好的回覆內容,切記要把內容說明清楚,甚至需要請 LLM 假設自己是什麼角色,這樣有助於 LLM 切換到合適的資料分類來進行內容推理哦!
例如,當你詢問 ChatGPT:「推薦一些增加軟體工程效率的工具」,可能會得到較一般的答案,可能會得到像 Figma, VSCode。
可以改成詢問 ChatGPT:「推薦一些增加軟體工程效率的工具,例如像是Github Copilot 能增加程式開發的效率,我想知道這類能提高速度的工具,包含系統分析、系統設計、系統測試」,此來你會得到比較不一樣的回覆,因為在 Prompt 給出了更明確的提示。
關於 Prompt 的三個提示重點如下:
♠ 引導模型生成特定內容:透過設計精確的提示,Prompt 可以引導生成模型產出更符合需求的回應,例如提供特定資訊、使用特定風格或語氣,或是聚焦於某一主題上。(簡單說就是告訴它你要什麼)
♠ 提升回應品質與準確性:設計合適的 prompt 能幫助模型理解問題的重點,從而減少誤解和不相關的回應,使輸出內容更加準確和有條理。
♠ 增強模型的問題回答能力:設計合適的 prompt 來引導模型準確理解問題類型,從而提供更精準的回答,尤其適合在客服或教育等需要精準解答的場合。
所以有想到了嗎?其實當你免費在用 ChatGPT 或 Gemini 時,就已經在協助作模型訓練了!但免費版本的不建議輸入相關隱私資訊。

♦ RAG 檢索增強生成 ♦
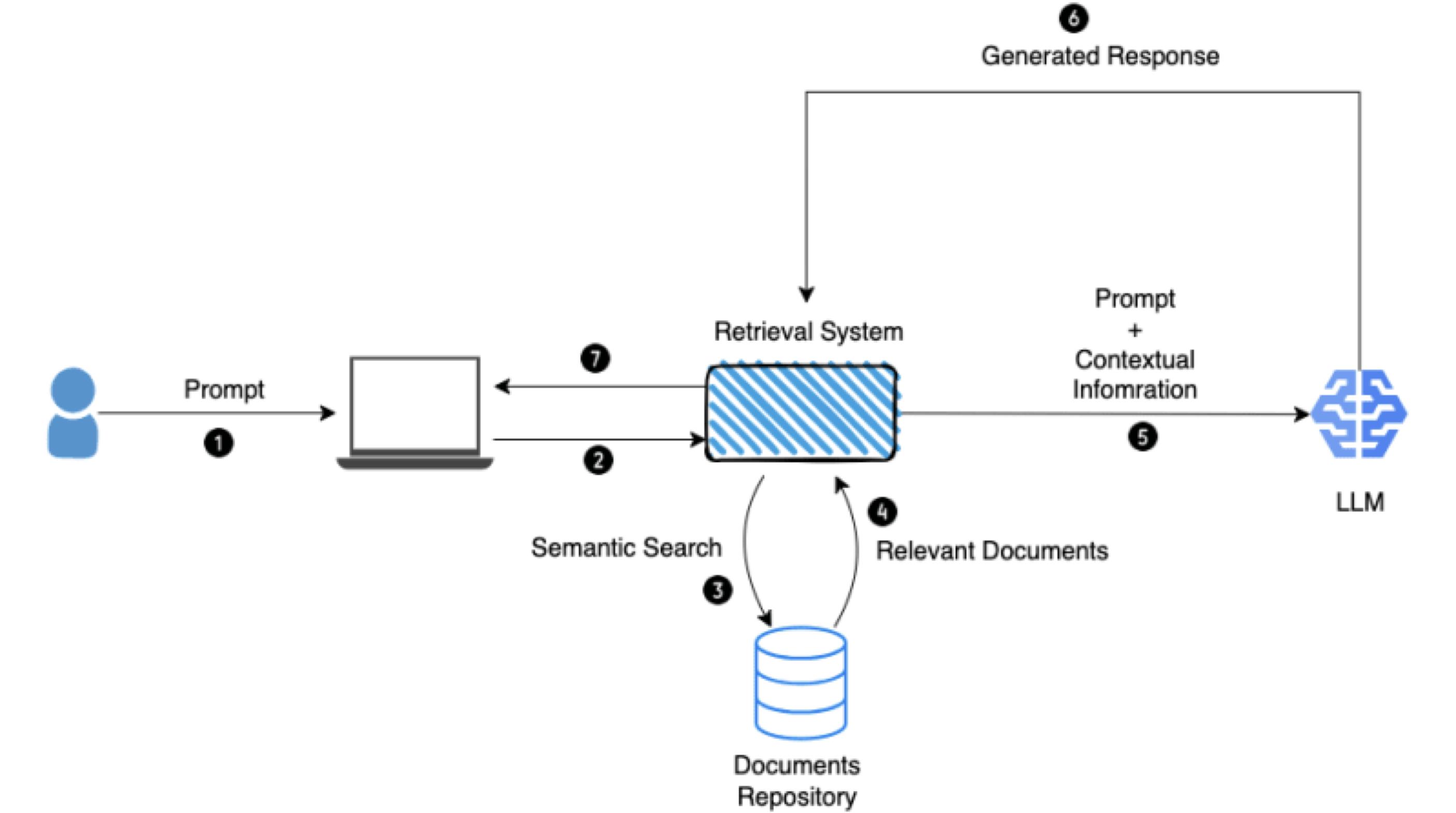
RAG 很好理解,它是對 LLM 輸出最佳化的過程,因此在產生回應之前,它會參考其訓練資料來源以外的權威知識庫。LLM 在大量資料上訓練,並使用數十億以上個參數來生成原始輸出,用於回答問題、翻譯語言和完成句子等任務。RAG 將原本就很強大的 LLM 功能擴展到特定領域或組織的內部知識庫,而無需重新訓練模型。這是改善 LLM 輸出具成本效益的方法,可讓 LLM 在各種情況下仍然相關、準確且有用。
RAG 也是作資訊系統開發導入 LLM 應用很常見的需求。
這裡以一個系統開發案件來作比喻,現在要開一個一套系統,系統需求是「自動化報告生成與數據分析」。AI 根據數據自動生成商業報告、行銷分析報告,甚至寫出 PowerPoint 簡報內容。讓用戶透過自然語言查詢數據,例如:「過去一個月的銷售趨勢?」
但問題來了,LLM 知道會知道公司的銷售數據?這時 RAG 就是很好的應用。簡單說,NLP(自然語言處理) 交給 LLM,但銷售資料可以是通過外部資料來提供給 LLM 整合內容再回覆的使用者。也就是公司的銷售資料並沒有在 LLM 的模型中,這部份可以通過 AI Agent 來作資料整合處理。
這部份應用在各行各業非常多,且通常中小企業不會訓練自己的 AI 模型,而搭配 LLM + RAG + Prompt 可以實現一些 AI 解決方案。
♦ Fine-Tune 微調 ♦
針對特殊任務需求時,在既有的 LLM 上藉由輸入與目的相關的專業資訊,來進行調整參數的模式訓練的方法。簡而言中,與 RAG 不同的是一個是針對外部資料,一個是針對 LLM 內部已存在的模型資料。將 LLM 內特定的資料領域進行調整優化這個動作就稱為 Fine-Tune。
其實包含作資料清理,以去除不必要的符號、錯誤,來讓 LLM 輸出內容更為準確。甚至也可以進行情感分析任務的微調,需要收集帶有情感標籤。來讓 LLM 能了解自然語言中如何透過文字理解情感和表達情感。
想像一下,一個預訓練好的 LLM 就如同一個博學多聞的人類,他對各種知識都有所涉獵。但如果我們想讓這個人成為一位專精於法律領域的律師,就需要對他進行更專業的訓練。微調的過程就類似於這種專業訓練。仔細想想,是不是相似人類讀到大學之後開始進行特殊專業技能學習呢?
那何時選擇 RAG,何時選擇要 Fine-Tune?

♦ 場景案例 ♦
這裡用兩個簡單的例子來總結 RAG 和 Fine-Tune 的應用面。
【分析金融市場的即時動態和數據】金融市場瞬息萬變,因此在執行任務時,無法僅依靠原本的學習資料庫,大語言模型需要結外部的金融市場資料庫。因此應該採用 RAG。
【分析醫療診斷報告】由於病患的醫療診斷數據來源相當多元,而且報告中也充斥著許多醫療的專有名詞,原本的通用型大語言模型可能要經過再學習的過程,才能夠符合特殊任務的使用。因此應該採用 Fine-Tune。
♦ 系統開發案例 ♦
文章前面的篇幅主要在說明 LLM 基本的概念組成,但這麼強大的語言模型得有要實際的產業應用,為人類作出貢獻才有它的價質的,單純拿 LLM 來作問答機器人實屬有些可惜。下面以一個用例來說明 LLM 除了作問答機器人,還能作到什麼應用。
我們現在知道語言模型之所以強大,是因為它能理解我們所問的問題,如果我們能運用它強大的文字分析能力的話,有助於建立高端的系統流程。
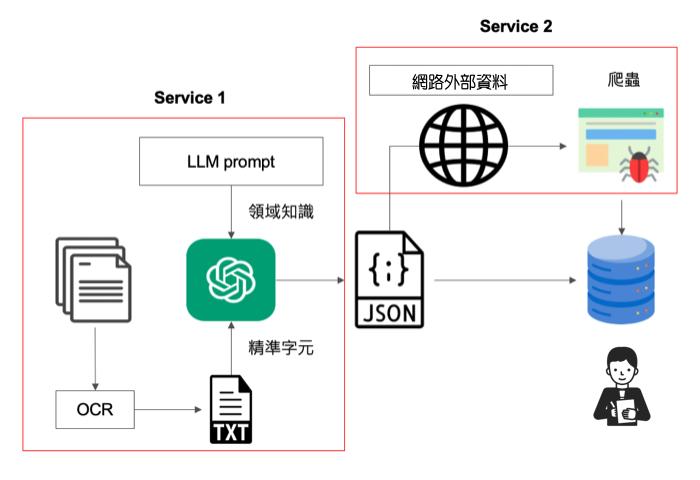
下面我舉一個文字辨識需求來說明,需求為「能辨識一份表格文件,將其表格中的欄位文字內容作提取後存入資料庫。」
以這個案子第一會使用到 OCR(光學字元辨識) 技術,但以目前的技術,OCR準確率無法確保其正確性,可能會因為文字難以辨識而辨識錯誤。這時我們可以運用 LLM 先將辨識出來的文字作第一層分析,並依照領域知識作可能性的調整,之後再通過外部的網頁資料 (可能是有公信力的網站系統),使用爬蟲方式進來資料比對,如此經過雙重比對分析後存入到資料庫中讓相關人員作審核。
這樣的方案有助於解決一開始就單純使用 OCR 將辨識出來的文字內容直接存入資料庫中,造成審核人員看到四不像的資料。
♦ AI Agent 代理人 ♦
你知道嗎?LLM 不知道現在時間是幾點幾分!除此之外 LLM 無法連網、無法記憶、知識更新不即時。
試想,如果你現在人是在一個荒島,但手上沒有手錶,即使你是一個大腦知識實分充足的人類,是否也無法知道當下的時間?是的,LLM 也是如此。因為 LLM 是一個語言模型,擅常的是文字語言,而非運算等等其他工作。
也就是一個強大的 LLM 本身會再串接不同的功能模組來滿足需求,就好像人類除了有智慧的大腦外,仍需要有一些工具來協助我們。而串接這些功能模組來達到做出決策並採取行動以實現特定任務能力就是 AI Agent。
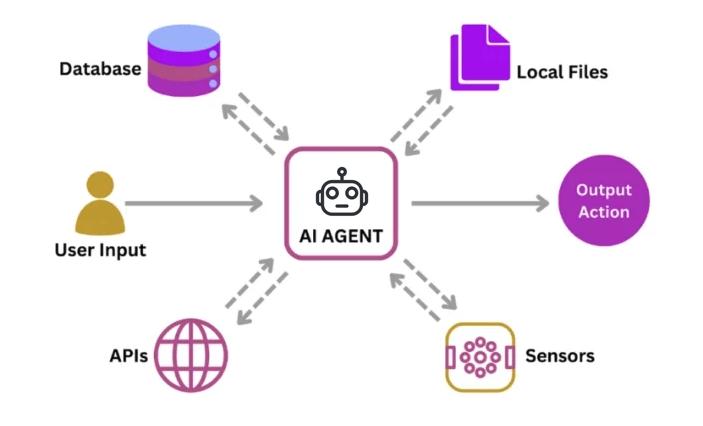
AI Agent 讓 LLM 從被動的指令執行者轉變成了主動的問題解決者。也就是說 AI Agent 是讓 LLM 落地在各問題解決方案的推手。
2024 是 AI Agent 的元年,以我個人的認知,AI Agent 將會陸陸續續在應用市場上出現。讓AI不僅僅是一門科學,更是協助人類解決問題的工具,例如個人化虛擬助理、自動駕駛、接待機器人等等。
♦ 結語 ♦
LLM 的迅速發展不僅在技術層面上帶來了突破,更在實際應用中展現了巨大的潛力。從最初的模型參數擴展,到後來的多模態應用,再到結合 RAG和 Fine-Tune 等優化技術,LLM 已經成為各行各業解決複雜問題的重要工具。更進一步,AI Agent 的崛起讓 LLM 不再只是被動的語言處理工具,而是能夠主動解決問題、整合多方資源的智能代理。
隨著技術的持續演進,未來的 LLM 將不僅僅停留在提升參數規模或增加語言理解能力,更將深度融入各種產業場景,協助人類解決更具挑戰性的問題。無論是在系統開發、商業分析,還是日常生活中,LLM 與 AI Agent 的結合將持續推動 AI 應用的邊界,為我們帶來前所未有的創新和便利。













