從生活了解Pandas – 多個檔案
簡介
整合複數Excel的資料常常令人頭痛,Pandas讓你省時又省心
而這次文章為貼近真實情境,會以Excel做範例,可以自己動手玩玩看喔!
情境:
想像你是一位水果店店長,手上拿到了兩份資料:
FruitColor 水果顏色對應表
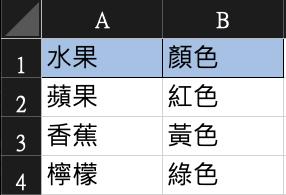
FruitPrice 水果價格表
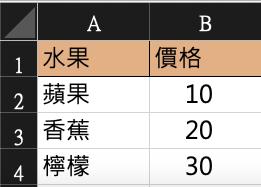
兩個檔案同時切換比對太麻煩了!
我們可以使用 join
data = data1.join(data2)
實際如下
import pandas as pd
Price_data = pd.read_excel('FruitPrice.xlsx' ,index_col=0)
Color_data = pd.read_excel('FruitColor.xlsx' ,index_col=0)
T_data = Price_data.join(Color_data)
T_data.to_excel('Total_data.xlsx')
這邊在路徑後面增加了index_col=0,告訴Pandas要以水果那一欄位底下的值為主
打開產生的檔案Total_data
Pandas 會幫我們把對應的資料排好--- 一目瞭然,太棒了 !
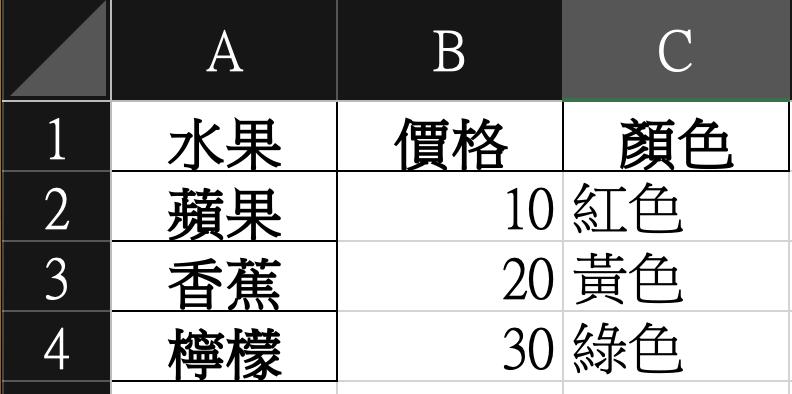
但是真實生活中,資料來源不可能這麼整齊,對吧?
過了幾天,我們拿到了新的表單:
Fruit_oulook
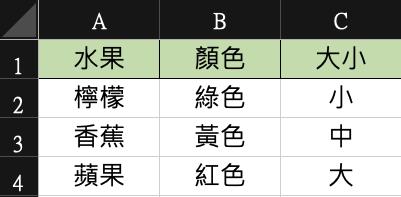
Fruit_value
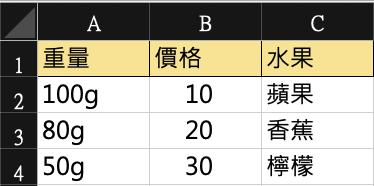
我們還是可以使用join,不過Fruit_value的水果欄位就要調整:
data1 = pd.read_excel(Fruit_outlook.xlsx' ,index_col=0)
data2 = pd.read_excel('Fruit_value.xlsx' ,index_col=2)
“欄位上百上千的話不就要數到眼花了嗎?!“
這時 merge 會是更好的選擇
Data=pd.merge(‘File1’, ‘File2’,on=’指定欄位名稱’)
實際如下
import pandas as pd
data1 = pd.read_excel('Fruit_outlook.xlsx')
data2 = pd.read_excel('Fruit_value.xlsx')
data3 = pd.merge(data1, data2 , on = '水果')
data3.to_excel('data3.xlsx')
結果會產生一個data3.xlsx的檔案
會依據指定的欄(水果),將對應的資料排好
細節補充
看到這邊,讀者應該會想問什麼時候用join 和 merge到底差在哪裡?
先說結論:在使用Excel的情境中,merge比較直觀且方便
差異比較如下:
欄列有別:
merge 預設以處理欄 (column)為主,不過也可以處理列(index)的值
join 只能處理列(index)的值
彈性:
merge 可以搭配 inner / outer 等不同語法,讓使用者可以在不同情境下應用
join 使用情境較單一
處理速度:
join 會比merge來得快(數據非常大量的話)
以上的比較都是建立在使用Pandas讀寫Excel資料的情境中,若是換到分析API, 爬蟲數據或函示庫…join 和 merge差異才會比較明顯
inner / outer
inner 只處理共同擁有的資料
outer 處理所有的資料,若有無法對應的資料,會顯示NaN
舉例如下:
import pandas as pd
# 範例資料庫
df1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value1': [1, 2, 3]})
df2 = pd.DataFrame({'key': ['B', 'C', 'D'], 'value2': [4, 5, 6]})
print('Original data:')
print(df1)
print(df2)
# Inner Merge
result_inner = pd.merge(df1, df2, on='key') # Returns only B and C
print("\nInner Merge:")
print(result_inner)
# Outer Merge
result_outer = pd.merge(df1, df2, on='key', how='outer') # Returns A, B, C, and D
print("\nOuter Merge:")
print(result_outer)
結果如下:
Original data:
key value1
0 A 1
1 B 2
2 C 3
key value2
0 B 4
1 C 5
2 D 6
Inner Merge:
key value1 value2
0 B 2 4
1 C 3 5
#inner 只處理共同擁有的資料
Outer Merge:
key value1 value2
0 A 1.0 NaN
1 B 2.0 4.0
2 C 3.0 5.0
3 D NaN 6.0
#outer 處理所有的資料,若有無法對應的資料,會顯示NaN
inner 也能當作一種篩選的方式
也可以用outer 搭配前一篇文章的replace,把NaN換成自己要的數值
總結
這次介紹了merge和join來處理複數檔案,Excel的情境下筆者會強烈建議使用merge,再搭配inner / outer 便能組合出自己想要的資料格式。 merge 還有 left / right 可以使用,但筆者認為 inner /outer 足以應付大多數情況,有興趣的讀者可以參考這篇文章
參考資料
https://datacomy.com/data_analysis/pandas/merge/
https://stackoverflow.com/questions/53645882/pandas-merging-101