Number Plate Detection Service By Using OpenCV
As previous: Quick Way To Identify A Number Plate By Using Azure Computer Vision topic's discussion, we will now do some effective upgrade.
Let's talk about it.
Basic Knowledge
-OpenCV
OpenCV (Open Source real-time Computer Vision Library that includes several hundreds of computer vision algorithms, it's originally developed by Intel.
Focusing the document describes us, the so-called OpenCV 2.x API, which is essentially a C++ API.
As opposed to the C-based OpenCV 1.x API (C API is deprecated and not tested with "C" compiler since OpenCV 2.4 releases)
-EmguCV
A cross platform .Net wrapper for the Open CV image-processing library. It allows Open CV functions to be called from .NET compatible languages. The wrapper can be compiled by Visual Studio, Unity and "dotnet" command, it can run on multiple platforms, such as Windows, Mac OS, Linux, iOS and Android.
And this should be our concern here.
Installation
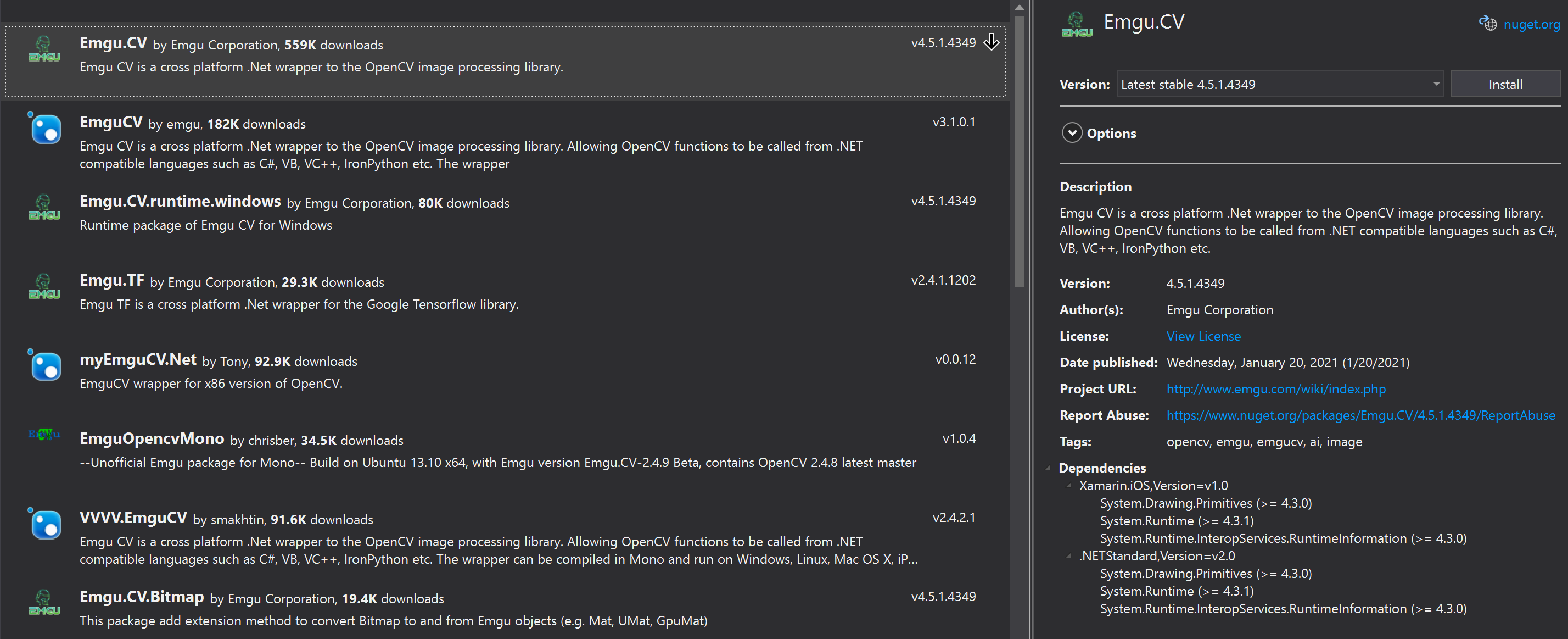
nuget Emgu.CV
PM> Install-Package Emgu.CV -Version 4.5.1.4349
or
CLI> dotnet add package Emgu.CV --version 4.5.1.4349
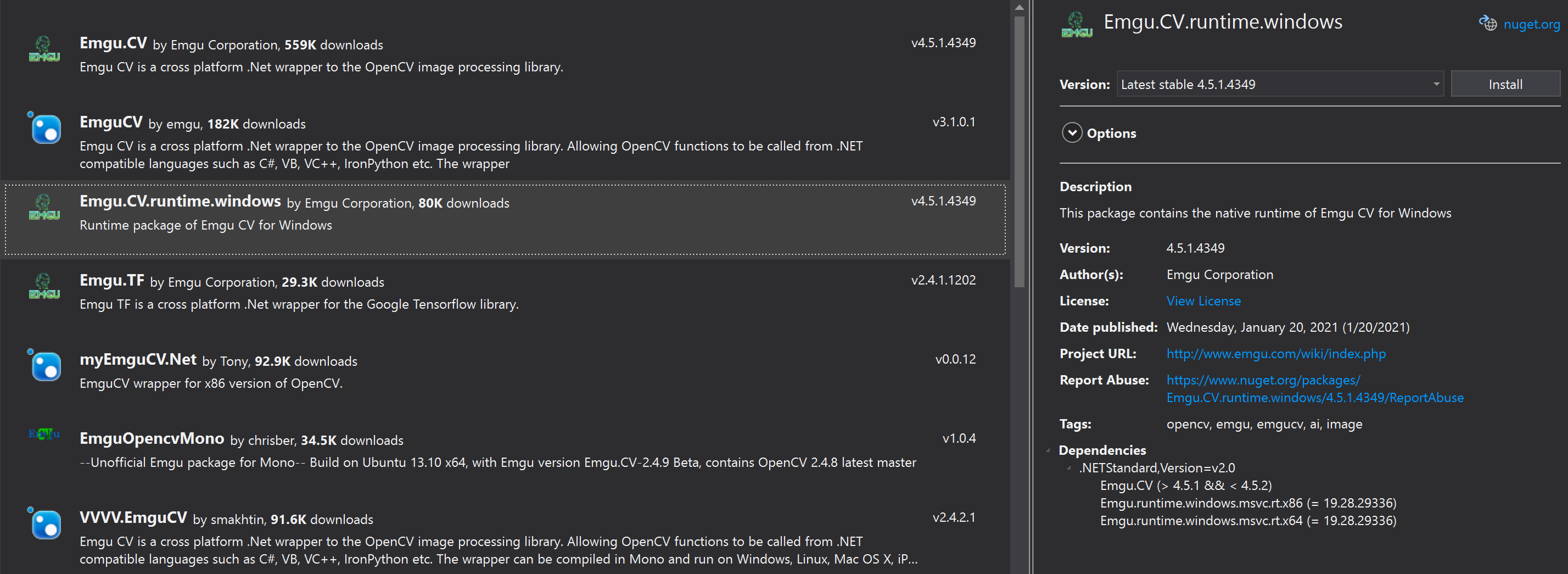
nuget Emgu.CV.runtime.windows
PM> Install-Package Emgu.CV.runtime.windows -Version 4.5.1.4349
or
CLI> dotnet add package Emgu.CV.runtime.windows --version 4.5.1.4349
Required files
These required files are so important for ocr detecting. Unfortunately, they did NOT include in EmguCV library. After a long time digging, we could grab them on github.
First, the (*).traineddata, aka. language file, they could be found and downloaded from github repo. They're binary files.
Second, trained_classifier_(*).xml, they also could be found and downloaded from github repo. They worked as path finder.
- trained_classifier_erGrouping.xml, 48KB
- trained_classifierNM1.xml, 47KB
- trained_classifierNM2.xml, 47KB
Find them all, place them in storage.
Workshop of OCR
Basicly, ocr are amounts of mathematical works. It took lots of CPU cycles to calculate. Oh, yes, if CPU could NOT provide high speed computing, it's bad for detecting performance.
Besides, if we got a high-end Nvidia video card installed on server/pc, we could also let the video card do the mathematical works (needs a nuget plugin, Emgu.CV.runtime.windows.cuda), and it should be run faster.
private Tesseract _ocr;
[HttpGet, Route("{ocrMode?}")]
public IActionResult Get(int ocrMode = 1)
{
_ocrMode = ocrMode;
if (InitOcr(Tesseract.DefaultTesseractDirectory, "eng", OcrEngineMode.TesseractLstmCombined))
{
if (new FileInfo(_numberPlateFilePath).Exists)
{
var img = new Mat(_numberPlateFilePath);
var ret = OcrImage(img, _classifierDataPath);
return Ok(ret);
}
return BadRequest($"{_numberPlateFilePath} did NOT exist.");
}
return Ok();
}
/// <summary>
/// ocr working initialize
/// </summary>
private bool InitOcr(string path, string lang, OcrEngineMode mode)
{
try
{
if (_ocr != null)
{
_ocr.Dispose();
_ocr = null;
}
if (string.IsNullOrEmpty(path))
path = Tesseract.DefaultTesseractDirectory;
TesseractDownloadLangFile(path, lang);
TesseractDownloadLangFile(path, "osd");
_ocr = new Tesseract(path, lang, mode);
Console.WriteLine($"{lang} : {mode} (tesseract version {Tesseract.VersionString})");
return true;
}
catch (Exception e)
{
_ocr = null;
Console.WriteLine(e.Message);
Console.WriteLine("Failed to initialize tesseract OCR engine");
return false;
}
}
/// <summary>
/// download lang file from github repo
/// </summary>
private void TesseractDownloadLangFile(string folder, string lang)
{
if (!Directory.Exists(folder))
{
Directory.CreateDirectory(folder);
}
string dest = Path.Combine(folder, $"{lang}.traineddata");
if (!System.IO.File.Exists(dest))
{
var source = Tesseract.GetLangFileUrl(lang);
Console.WriteLine($"Downloading file from '{source}' to '{dest}'");
using var fileStream = _httpClient.GetStreamAsync(source).Result;
using var f = System.IO.File.Create(dest);
fileStream.CopyTo(f);
fileStream.Flush();
Console.WriteLine("Download completed");
}
}
/// <summary>
/// The OCR mode
/// </summary>
private enum OCRMode
{
/// <summary>
/// Perform a full page OCR
/// </summary>
FullPage,
/// <summary>
/// Detect the text region before applying OCR.
/// </summary>
TextDetection
}
private OCRMode Mode =>
_ocrMode == 0 ? OCRMode.FullPage : OCRMode.TextDetection;
private static Rectangle ScaleRectangle(Rectangle r, double scale)
{
double centerX = r.Location.X + r.Width / 2.0;
double centerY = r.Location.Y + r.Height / 2.0;
double newWidth = Math.Round(r.Width * scale);
double newHeight = Math.Round(r.Height * scale);
return new Rectangle((int)Math.Round(centerX - newWidth / 2.0), (int)Math.Round(centerY - newHeight / 2.0),
(int)newWidth, (int)newHeight);
}
private static string OcrImage(Tesseract ocr, Mat image, OCRMode mode, Mat imageColor, string classifierDataPath)
{
var drawCharColor = new Bgr(Color.Red);
if (image.NumberOfChannels == 1)
CvInvoke.CvtColor(image, imageColor, ColorConversion.Gray2Bgr);
else
image.CopyTo(imageColor);
if (mode == OCRMode.FullPage)
{
ocr.SetImage(imageColor);
if (ocr.Recognize() != 0)
throw new Exception("Failed to recognizer image");
var characters = ocr.GetCharacters();
if (characters?.Any() == true)
{
var imgGrey = new Mat();
CvInvoke.CvtColor(image, imgGrey, ColorConversion.Bgr2Gray);
var imgThresholded = new Mat();
CvInvoke.Threshold(imgGrey, imgThresholded, 65, 255, ThresholdType.Binary);
ocr.SetImage(imgThresholded);
characters = ocr.GetCharacters();
imageColor = imgThresholded;
if (characters?.Any() == true)
{
CvInvoke.Threshold(image, imgThresholded, 190, 255, ThresholdType.Binary);
ocr.SetImage(imgThresholded);
characters = ocr.GetCharacters();
imageColor = imgThresholded;
}
}
foreach (Tesseract.Character c in characters)
{
CvInvoke.Rectangle(imageColor, c.Region, drawCharColor.MCvScalar);
}
return ocr.GetUTF8Text();
}
else
{
var checkInvert = true;
Rectangle[] regions;
var erf1 = Path.Combine(classifierDataPath, "trained_classifierNM1.xml");
var erf2 = Path.Combine(classifierDataPath, "trained_classifierNM2.xml");
using var er1 = new ERFilterNM1(erf1, 8, 0.00025f, 0.13f, 0.4f, true, 0.1f);
using var er2 = new ERFilterNM2(erf2, 0.3f);
var channelCount = image.NumberOfChannels;
var channels = new UMat[checkInvert ? channelCount * 2 : channelCount];
for (var i = 0; i < channelCount; i++)
{
var c = new UMat();
CvInvoke.ExtractChannel(image, c, i);
channels[i] = c;
}
if (checkInvert)
{
for (var i = 0; i < channelCount; i++)
{
var c = new UMat();
CvInvoke.BitwiseNot(channels[i], c);
channels[i + channelCount] = c;
}
}
var regionVecs = new VectorOfERStat[channels.Length];
for (var i = 0; i < regionVecs.Length; i++)
{
regionVecs[i] = new VectorOfERStat();
}
try
{
for (var i = 0; i < channels.Length; i++)
{
er1.Run(channels[i], regionVecs[i]);
er2.Run(channels[i], regionVecs[i]);
}
using var vm = new VectorOfUMat(channels);
var classifier = Path.Combine(classifierDataPath, "trained_classifier_erGrouping.xml");
regions = ERFilter.ERGrouping(image, vm, regionVecs, ERFilter.GroupingMethod.OrientationHoriz, classifier, 0.5f);
}
finally
{
foreach (var tmp in channels)
{
if (tmp is not null) tmp.Dispose();
}
foreach (var tmp in regionVecs)
{
if (tmp is not null) tmp.Dispose();
}
}
var imageRegion = new Rectangle(Point.Empty, imageColor.Size);
for (var i = 0; i < regions.Length; i++)
{
var r = ScaleRectangle(regions[i], 1.1);
r.Intersect(imageRegion);
regions[i] = r;
}
var allChars = new List<Tesseract.Character>();
var allText = new StringBuilder();
foreach (var rect in regions)
{
using var region = new Mat(image, rect);
ocr.SetImage(region);
if (ocr.Recognize() != 0)
throw new Exception("Failed to recognize image");
var characters = ocr.GetCharacters();
//convert the coordinates from the local region to global
for (var i = 0; i < characters.Length; i++)
{
var charRegion = characters[i].Region;
charRegion.Offset(rect.Location);
characters[i].Region = charRegion;
}
allChars.AddRange(characters);
allText.Append(ocr.GetUTF8Text() + Environment.NewLine);
}
var drawRegionColor = new Bgr(Color.Red);
foreach (var rect in regions)
{
CvInvoke.Rectangle(imageColor, rect, drawRegionColor.MCvScalar);
}
foreach (Tesseract.Character c in allChars)
{
CvInvoke.Rectangle(imageColor, c.Region, drawCharColor.MCvScalar);
}
return allText.ToString();
}
}
private string OcrImage(Mat source, string classifierDataPath)
{
try
{
var result = new Mat();
var ocredText = OcrImage(_ocr, source, Mode, result, classifierDataPath);
if (Mode == OCRMode.FullPage)
{
return _ocr.GetHOCRText();
}
return ocredText;
}
catch
{
throw;
}
}
The full sample code is stored on gist, please take a look at it and try it.
The Result
While api called, we saw some result texts showing. Of course, there should be contained some noise on it. We still need to find a way to rid them off.
Enjoy it.
Cover image from: https://unsplash.com/photos/5_o-FheeEi0
References:













