Java辨視中文的編碼格式-Big5、UTF8
1. 目的
對於開發人員來說,Java程式語言需要明確指定並處理文字編碼是理所當然的事,除了執行環境的編碼之外,IO也是需要注意的部分。在許多資料串接或是遺留系統上,編碼與現行環境或使用需求有可能出現較複雜的處理情境,尤其是早期編碼環境流行使用Big5,即可能發生與UTF-8交互使用而衍生一些問題;或是Windows環境的造字問題等。因此,文字編碼的處理與判斷問題,總是不斷發生,本文即針對此問題進行驗證。
2. 開始前準備
• Eclipse
• JDK 1.8
• cpdetector 1.0.10
• chardet 1.0
3. 撰寫編碼驗證程式
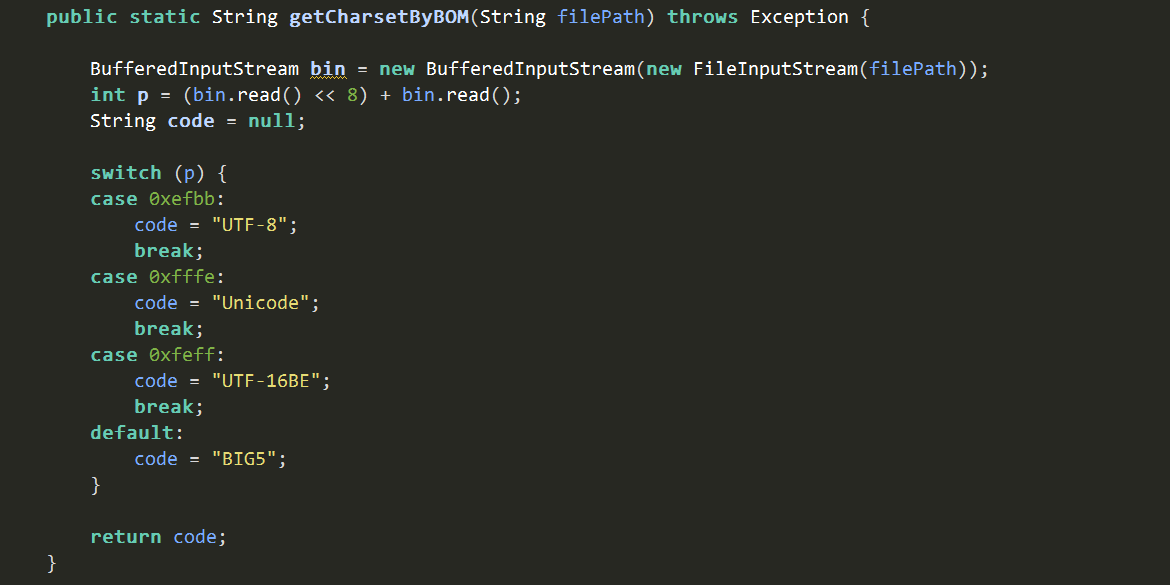
3.1. 以檔首BOM來檢查文字檔案編碼
利用Unicode的檔首BOM來檢查是否文字檔案編碼為UTF-8,無BOM則當作是Big5。
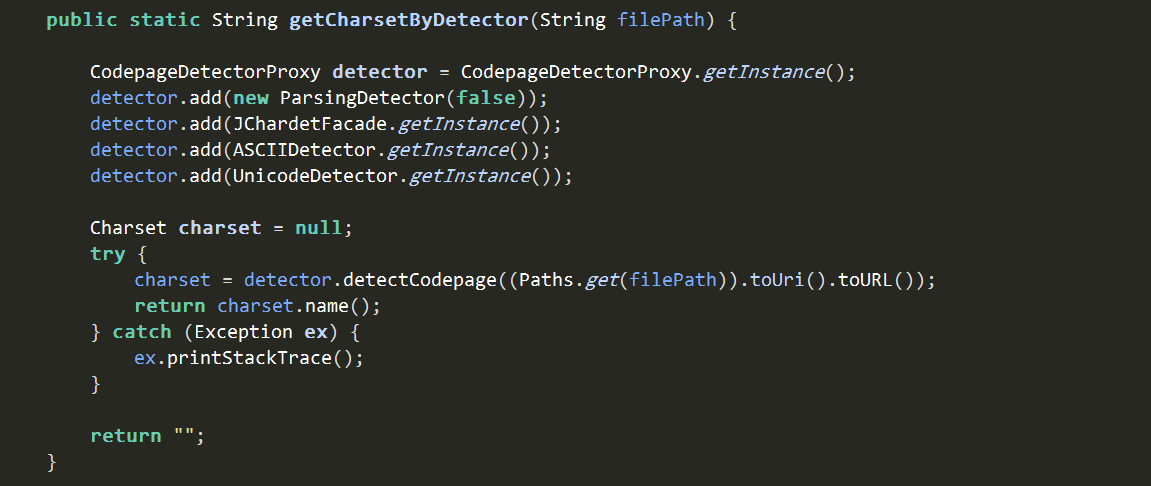
3.2. 以套件cpdetector檢查文字檔案編碼
cpdetector套件協助檢查編碼(其中JChardetFacade包含了使用Mozilla的JChardet),並且可以再增加探測器,如ASCIIDetector及UnicodeDetector。
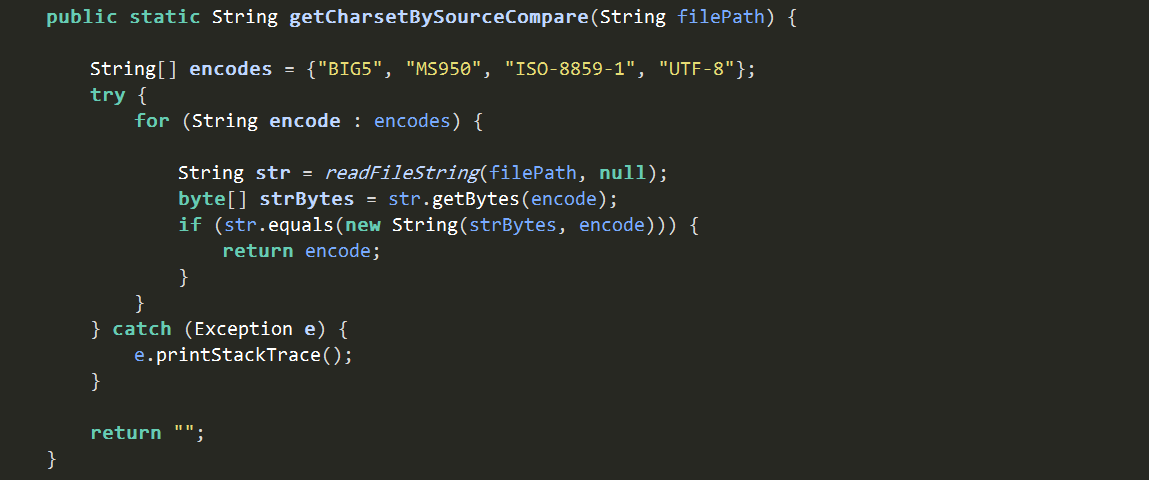
3.3. 以轉碼前後文字比較檢查文字檔案編碼
以byte方式指定編碼再轉碼後與原始文字進行比較,其中特別指定了Windows系統中的預設編碼MS950。
4. 建立測試編碼用文字檔
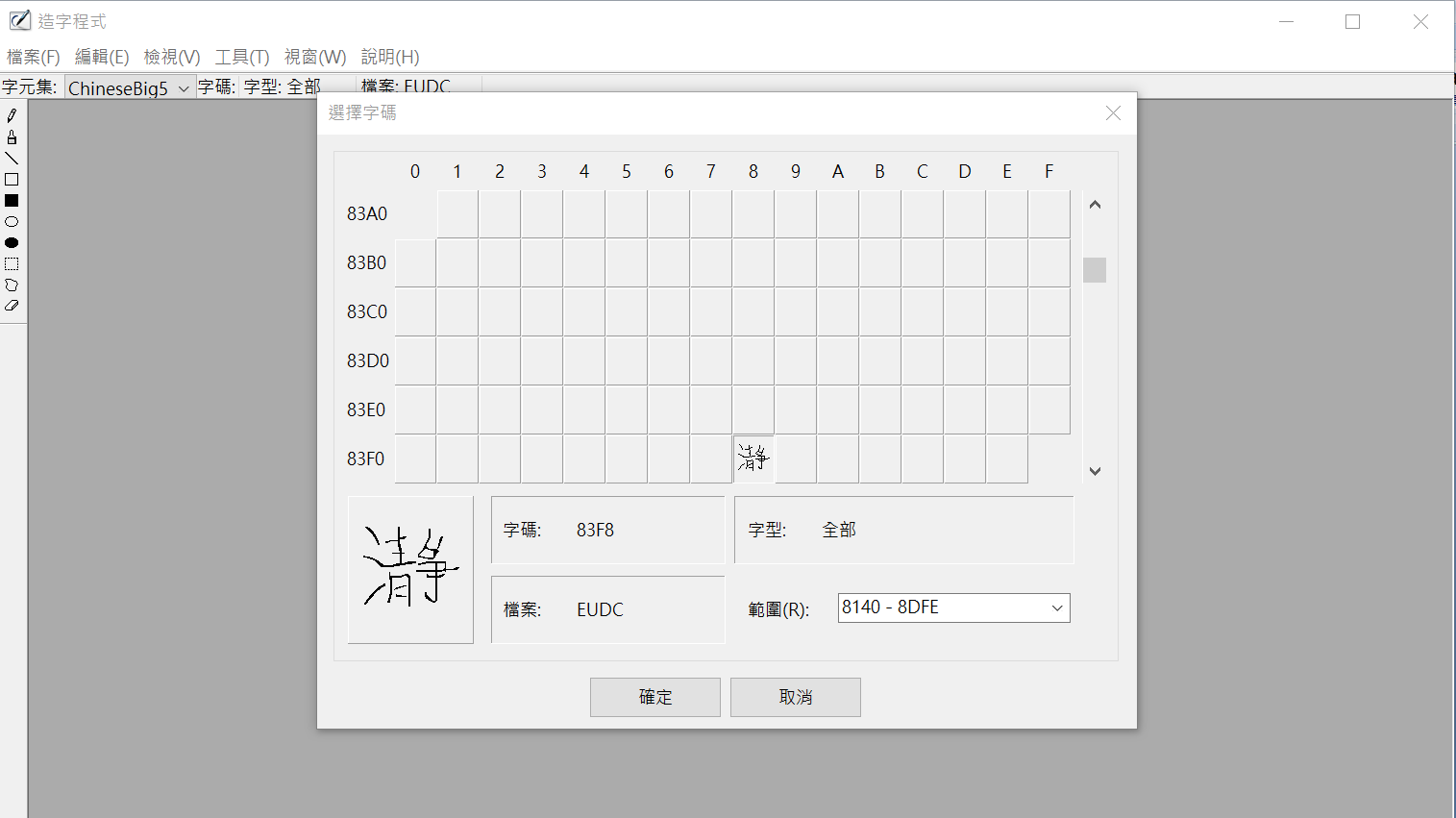
建立Big5、UTF-8(有檔首BOM)、UTF-8(無檔首BOM)三分檔案,內容包含中、英文及造字文字。
Big5:

UTF-8(有檔首BOM):

UTF-8(無檔首BOM):

Windows自行造字:
5. 編碼檢查驗證結果
撰寫測試程式,呼叫本文設計的三種檢查編碼方式,記錄花費時間及利用檢查取得編碼來讀取文字檔案,並顯示log在console以方便人為檢視結果。
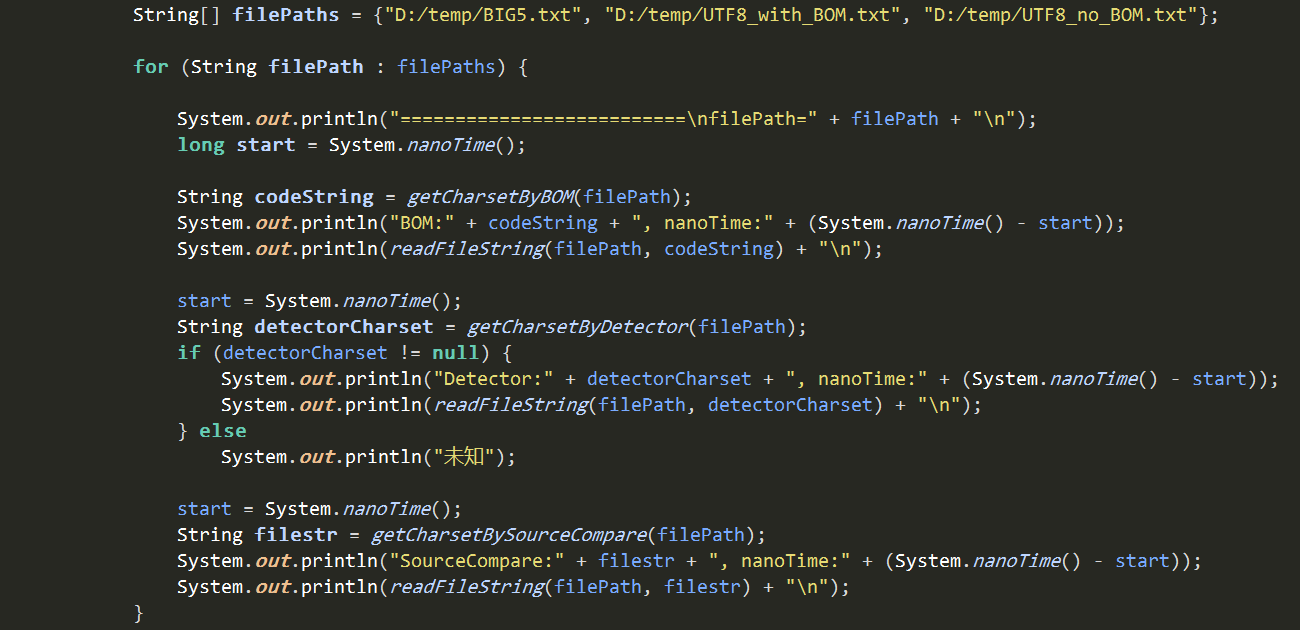
> 檢查Big5編碼文字檔案結果:
. 以檔首BOM來檢查文字檔案編碼,由於Big5沒有檔首BOM,故判定結果為預設編碼的Big5,但由於內容包含了造字文字,Java並沒有辦法正確用Big5來顯示文字內容,造字部分發生錯誤而顯示為亂碼。
. 以套件cpdetector檢查文字檔案編碼,判斷結果是UTF-16LE,Java以該編碼顯示全為亂碼。
. 以轉碼前後文字比較檢查文字檔案編碼,判斷結果是MS950,Java正確以該編碼顯示原始內容。
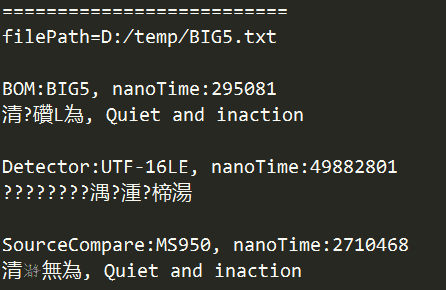
> 檢查UTF-8(有檔首BOM)編碼文字檔案結果:
. 以檔首BOM來檢查文字檔案編碼,正確識別了文字內容為UTF-8,Java即顯示了原始內容,但由於包含BOM的關係,故多出現了一個問號(?)。
. 以套件cpdetector檢查文字檔案編碼,也判斷正確。
. 以轉碼前後文字比較檢查文字檔案編碼,也判斷正確。
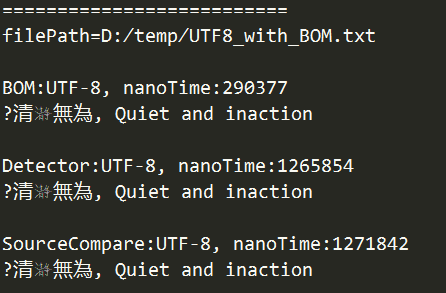
> 檢查UTF-8(無檔首BOM)編碼文字檔案結果:
. 以檔首BOM來檢查文字檔案編碼,由於內容沒有檔首BOM,故判定結果為預設編碼的Big5,Java以編碼顯示內容即為亂碼。
. 以套件cpdetector檢查文字檔案編碼,判斷正確。
. 以轉碼前後文字比較檢查文字檔案編碼,也判斷正確。
綜合以上結果,僅以檔首BOM來檢查編碼確實不適當;套件cpdetector似乎對於中文環境常有的造字有辨視錯誤問題;以轉碼前後文字比較方式檢查在此驗證中是可行的方式,雖然可能發生大量轉碼的效能疑慮,但仍不失為可應對的方向之一。
6. 參考來源
- cpDetector-https://sourceforge.net/projects/cpdetector/













