News Recommendations in Neo4j
Table Of Contents
Introduction
Dataset
Basic Cypher Queries for Collaborative Filtering
Scaling Collaborative Filtering: Node Embedding and K-Nearest-Neighbor(KNN)
延續上一篇Graph Embeddings in Neo4j 利用Neo4j GDS執行圖嵌入(Graph Embedding),相信大家對圖嵌入也有相對的了解。
下一步我們將通過一個新聞推薦數據集來介紹一個基本範例。將利用圖嵌入(Graph Embedding) 結合協同過濾(Collaborative Filtering) 根據用戶偏好快速預測類似新聞。

Almost 100k users and their MSN news click behaviors. Made publically available by Microsoft.
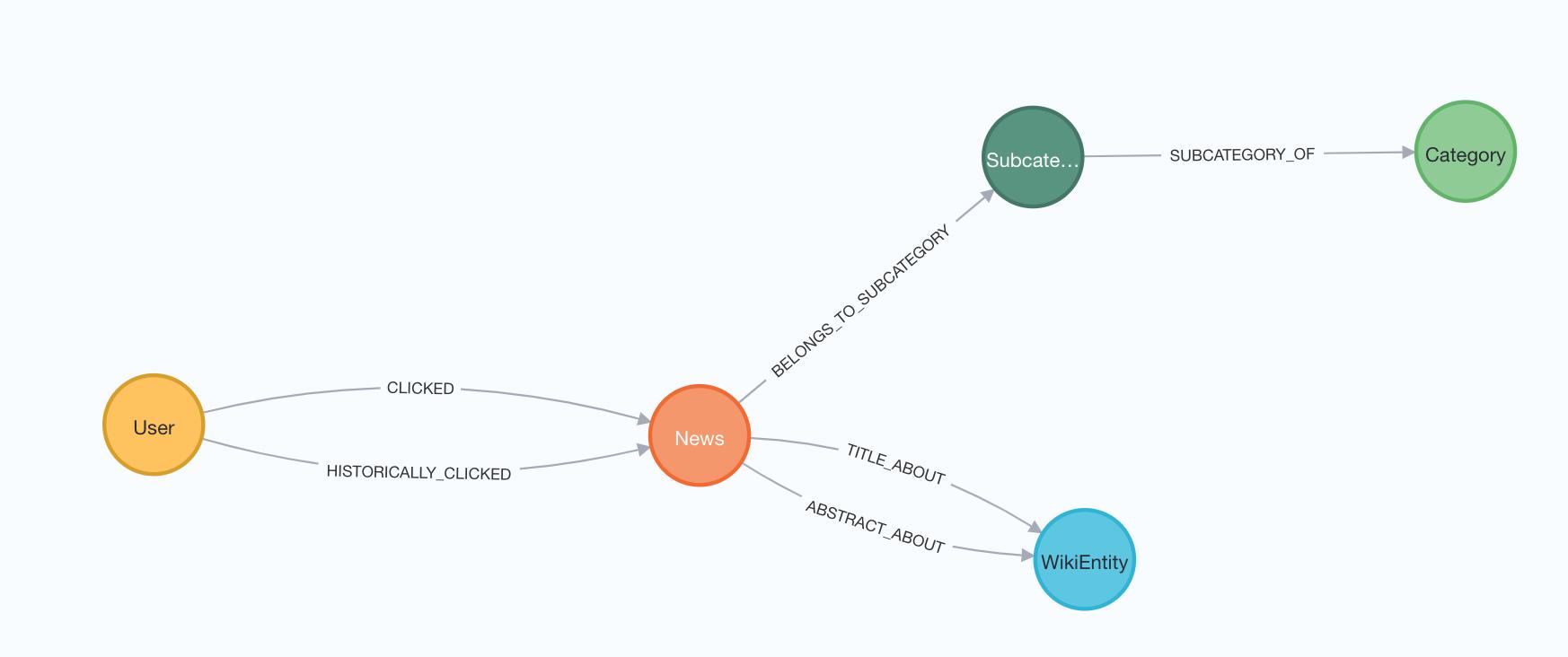
- Neo4j: 4.4.4
- APOC library: 4.4.0.3
- Graph Data Science (GDS) Library = 1.8.6
為了確保Collaborative Filtering(CF)推薦是相關的,我們需要過濾到新聞文章的子集。
最近的新聞往往是最相關的,隨著時間的推移,可能很快失去相關性。一般來說,好的新聞推薦應該避免陳舊和/或過時的新聞。在這種情況下,我們可以使用Microsoft impression 作為代理,並且只考慮在我們的示例時間範圍內的這些新聞。為此,我們可以使用一個名為approxTime的節點屬性,它反映了新聞文章的最小impression時間。我在將源數據加載到Neo4j時計算了這個屬性。
Collaborative Filtering(CF)的一個限制是它只能推薦帶有用戶反饋的內容。因此,沒有用戶點擊的新聞文章在這裡不能用於Collaborative Filtering(CF)。在實務上,這有時被稱為冷啓動問題。它可以通過基於內容的推薦和其他混合方法來解決。但在這個例子中,我們只考慮至少有一個用戶點擊的新聞文章,即至少有一個CLICKED或HISTORICALLY_CLICKED關係。
我們可以指定第二個節點標籤,RecentNews,讓我們可以很容易地過濾到符合上述Cypher查詢和GDS預測標準的新聞。

推薦系統有許多不同的類型。在本例中,我們將應用一種稱為協同過濾(Collaborative Filtering)的技術,該技術可以根據相似用戶的行為自動預測用戶的偏好。
協同過濾主要分成兩種:
1. 基於用戶(User-based),重點是根據用戶與物品的交互直接計算用戶之間的相似度
2. 基於項目(Item-based),它根據相關的用戶活動(比如相同的用戶喜歡、觀看、評級或其他類似的與項目的交互)來衡量項目對之間的相似性
我們今天的方法將側重於後者,即基於項目(Item-based)的協同過濾。
Basic Cypher Queries for Collaborative Filtering:
從這裡我們可以嘗試只使用 Cypher 來完成基本的協作過濾。 例如,以下面的用戶(U91836)和他點擊的新聞為例。 可以看到金融、新聞和其他幾個類別之間的混合興趣。

假設我們可以通過經常點擊的新聞文章來衡量用戶興趣的相似度,那麼我們可以根據用戶點擊與U91836相同新聞的用戶的活動來進行三跳查詢,從而找到用戶U91836的潛在推薦。
通過下面的查詢,我們可以得到需要遍歷的節點的總數,以獲得建議。

Scaling Collaborative Filtering: Node Embedding and KNN:
在Neo4j GDS,我們可以使用 FastRP 節點嵌入來降低問題的維數,然後使用稱為 K-Nearest Neighbor (KNN) 的無監督機器學習技術來識別和繪製具有相似/接近嵌入的新聞之間的推薦。
FastRP

KNN
運行 KNN 並將相似性透過新創關係(USERS_ALSO_LIKED)寫回圖中

Result
透過剛剛計算出來的相似分數,依照分數高低推薦新聞給用戶U91836














