NoSQL + MongoDB + gudab介紹與應用
NoSQL + MongoDB + gudab介紹與應用
| 簡介 |
21世紀互聯網的興起,巨量資料在網路上流通,帶動了NoSQL的蓬勃發展。內文將重點介紹:NoSQL的定義和分類、MonogDB的功能和系統架構、資料庫監控工具- gudab、個案研究-影像流程系統、硬體規格建議。 |
| 作者 |
莊興旺 |
NoSQL + MongoDB + gudab介紹與應用
NoSQL介紹
NoSQL 的定義
NoSQL這個名詞,多數人聽到的解釋為 Not Only SQL,但從字面上很難明白代表的意義。事實上,這個名詞包含多種新興資料庫,故沒有一致的定義。
如維基百科在概念不明確的情況下,給了反面解釋。
NoSQL是對不同於傳統的關聯式資料庫的資料庫管理系統的統稱 (維基百科)
但是,我們能透過下列多數 NoSQL資料庫的共通特性,劃分 RDBMS 與 NoSQL 資料庫的邊界,而本文後半將重點介紹 NoSQL領頭羊 - MongoDB。
1. 為21世紀互聯網(Intenet)盛行後誕生。由於家用網路和智慧手機盛行、資料量變大,網路資料交換使用豐富的資料結構 JSON、XML。
2. 通常有水平擴展(scale-out)的能力。多依照分散式架構設計(不包含圖形資料庫)。
3. 通常不使用關聯模型。不做正規化、不支持SQL語法和JOIN操作。將聚集後的資料作為儲存的最小單位,透過豐富的資料結構,有利於將資料分散到多個節點。
4. 不需要事先建立固定的表格模式,也就是無模式(schema free)。
5. 開放原始碼
而用戶對NoSQL的興趣,來自於RDBMS面臨的3大難題。
傳統RDBMS是設計在單個節點上運作,但凡需要增加系統資源,垂直擴展(scale-up)所費不貲而且會有硬體瓶頸。反之,NoSQL通常有水平擴展的能力,藉由多個一定水準的商用硬件(x86 Server),分別處理部分的資料,有效打破硬體瓶頸造成的效能問題。
記憶體和資料庫的資料結構不同,讓開發者無法直覺的處理資料,需要透過ORM解決方案(例.Hibernate)和執行SQL JOIN,造成系統效能不佳。
另外,若資料欄位有異動時,需要聯繫DBA修改模式,不利開發。
3. 過於複雜關係
有時需要從多個表格做JOIN操作,才能呈現複雜的關係,但這種操作嚴重影響系統效能。反之,NoSQL的圖形資料庫,透過寫入資料時,預處理圖形節點間的關係,來保證查詢時的效能。
NoSQL 的分類
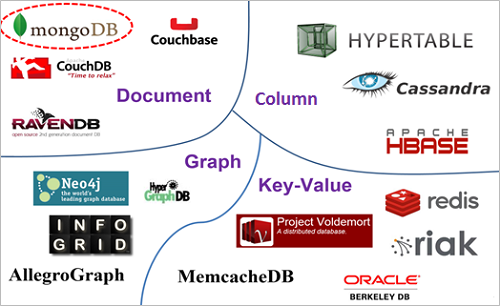
從資料模型的角度,可以劃分成四種:
1. 文檔資料庫(Document)
廣泛應用在各種場景(不支持事務型系統),與欄位群資料庫相比更適合靈活查詢。
2. 欄位群資料庫(Column-family)
廣泛應用在各種場景(不支持事務型系統),與文檔資料庫相比更適合寫入操作。
3. 鍵值資料庫(Key-value)
只能透過key來查詢,並將value視為一個Object,故無法取出Object裡的部分欄位。適合儲存用戶訊息,例如:購物車、web session。
4. 圖形資料庫(Graph)
節點與連線所構成的圖形資料結構。適合記錄複雜關係的資料,例如:社群網路、推薦引擎、運輸路線等關係性強的場景。
前三者為聚集導向的資料庫,適合建立在分散式架構處理巨量資料,但通常不支持ACID Transaction。
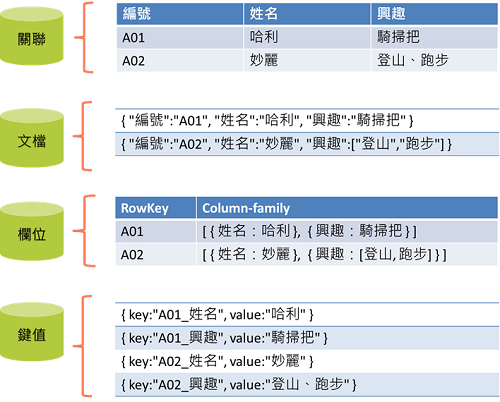
最後一個圖形資料庫,適合建立在單一伺服器處理複雜關係,支持ACID Transaction,但同樣不支持關聯模型。
NoSQL 之 CAP 定理
聚集導向的NoSQL,通常設計成分散式架構,而分散式系統有一個著名的CAP定理,指出系統只能同時滿足CAP 當中的兩項。
l Consistence(一致性)
一致性,不管何時何地,只要請求有所回應,那得到的資料皆為最新,但不保證每次請求都能立即得到結果。
l Availability(可用性)
保證每一次請求都可以立即得到非錯的結果,但不保證資料是最新的。
l Partition-tolerance(分區容錯性)
當分散式系統原本通順的網路,因為發生網路延遲或中斷,導致節點之間無法在限定時間完成通信(形成分區),系統仍能正常運行。
因此,用戶必需根據應用場景,選擇適合的資料庫。
l CA(一致性、可用性)
資料庫代表為RDBMS, Greenplum, Vertica …,通常在水平擴展上不太強大。想像兩個節點(X、Y),對應用程式可用,為了X節點更新時滿足一致性,故X與Y需要溝通協調至一致,不能有分區,故犧牲分區容錯性。
l CP(一致性、分區容錯性)
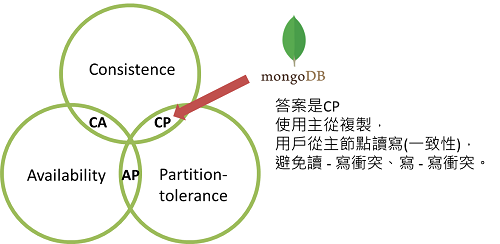
資料庫代表為MongoDB, Hbase, Redis …,與符合AP的資料庫相比,通常寫入效能較低。想像兩個節點(X、Y),分處"分區"兩側(彼此無法溝通),為了X節點更新時滿足一致性,故Y需要對應用程式不可用,避免取到舊資料,故犧牲可用性。
l AP(可用性、分區容錯性)
資料庫代表為Cassandra, Dynamo, CouchDB …,與符合CP的資料庫相比,通常應用程式對一致性的要求較低。想像兩個節點(X、Y),分處"分區"兩側(彼此無法溝通),為了分區時滿足可用性,故允許X更新時造成與Y資料不一致,但可能讓多個應用程式存取到不同數值,故犧牲一致性。
Q. 想一想,MongoDB歸類於CAP哪兩者交集?
MongoDB介紹
資料庫排名
l DB-ENGINES 調查報告,MongoDB是 NoSQL 的第 1 名,所有資料庫的第 5 名。

l Stackoverflow 調查報告,MongoDB是最多人想嘗試(Wanted)的第1名,是最多人喜愛(Loved)的第7名。

基礎認識
MongoDB 是現在最流行的 NoSQL 資料庫,提供用戶:
l 加速開發效率
l 處理大量資料
l 降低成本支出
小典故
l 名字起源於 "humongous" (堆積如山)
l 創始者希望使用者覺得簡單自然,因此 Logo 是一片葉子。

設計理念採用Nexus架構,也就是集RDBMS和NoSQL兩家的優點。
l RDBMS:豐富的查詢語法、強一致性、企業級工具 …。
l NoSQL:靈活的資料結構、水平擴展的效能、全球化佈署 …。
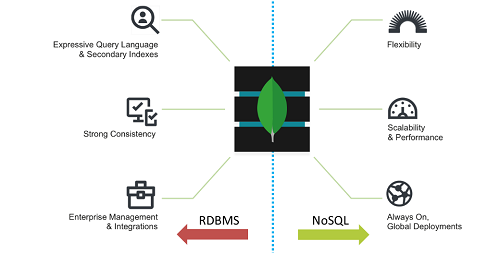
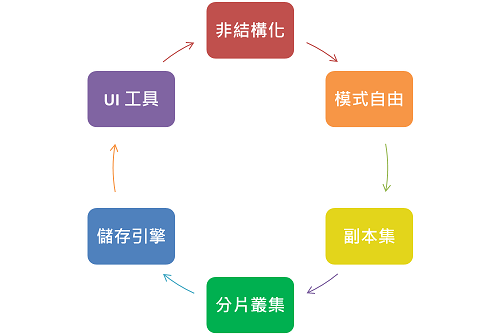
依個人經驗,總結MongoDB 6大特點。
1. 非結構化:適合儲存非結構化、半結構化(JSON,XML)資料。
2. 模式自由(schema free):開箱即用,不用預定義。
3. 副本集:透過複製,讓多個節點維護相同資料,可分散讀取請求,提高讀取效能。
4. 分片叢集:透過分片,讓資料分散到多個節點,可分散寫入請求,提高寫入效能。
5. 儲存引擎:可根據應用場景,抽換儲存引擎。
Ø MMAPv1:早期的引擎,表現良好。
Ø WiredTiger:3.0版本後預設的引擎,提供壓縮和高效能。
Ø In-memory:資料不落地,放在記憶體中。
Ø Encrypted engine:資料落地時,檔案額外加密。
6. UI工具:工具非常豐富,例. gudab、Robo 3T、Ops Manager、Compass …。
MongoDB還有其他功能特色,包含但不限於以下特點:
免費、開源、豐富的查詢語法、支持次級索引、對開發者友善、容易佈署、參考文檔豐富、學習曲線低、部分近似 RDBMS。
RDBMS面向切入
下面從 RDBMS 的 4 個面向,和 MongoDB 做比較
1. 執行檔名稱
l mongod是啟動DB用的執行檔
l mongo是與mongod交互的shell,採用 JavaScript interface。

2. 術語和概念
l 術語的差異Table/Collection、Row/Document。
l 觀念的差異 Join/Embedding、Schema Fixed/Schema Free、Scale-up/Scale-out。

3. 資料模型
l Relation模型:採用SQL的JOIN操作(查詢多個表格)。
l Document模型:採用 Embedding方式,避免多次查詢。

4. CRUD 語法
下列依序為SQL和mongo shell新增、查詢、修改、刪除的語法對照。可以發現,MongoDB的語法較符合Object-Oriented。
l INSERT INTO people(user_id, age, status) VALUES ("bcd001", 45, "A")
Ø db.people.insertOne( { user_id: "bcd001", age: 45, status: "A" } )
l SELECT * FROM people
Ø db.people.find()
l UPDATE people SET status = "C" WHERE age > 25
Ø db.people.updateMany( { age: { $gt: 25 } }, { $set: { status: "C" } } )
l DELETE FROM people WHERE status = "D"
Ø db.people.deleteMany( { status: "D" } )
MongoDB系統架構
Standalone 單機
l 適合測試環境、快速開發。
l 預設為27017埠。
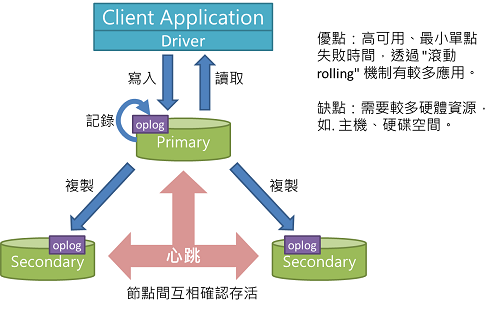
Replica Set 副本集
l 適合正式環境、資料量小、資料量固定。
l 透過複製(Replication),由多個節點維護同一份資料,能有效提高讀取效能。
l MongoDB採用主從式複製,主節點(Primary)接受應用程式讀寫操作,而從節點(Secondary)僅接受讀操作。
l 提供高可用HA,屬於active-standby機制。當Primary掛掉時,由Secondary 提供熱備份,從Secondary重新選出新的Primary做容錯移轉(fail-over)。
l Primary記錄應用程式的操作日誌(oplog),作為Secondary的同步源。
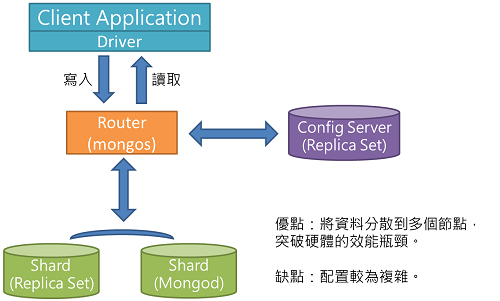
Sharded Cluster 分片叢集
l 適合正式環境、資料量大、資料量持續增長。
l 透過分片(Sharding),將一份資料分散到多個節點,能有效提高寫入效能。
l MongoDB透過Router(mongos)作為應用程式的入口,將整個分片叢集視為單機資料庫,有效降低開發複雜度。而Config Server會記錄路由規則等中繼資料。
l 建議在巨量資料的情境,一開始就使用分片叢集。因為等資料量過多才分片,會造成大量資料分流其他分片,不僅吃資源而且費時。
gudab介紹
企業級MongoDB監控管理平台
gudab產品官網https://www.gudab.com/cht/#Download,提供 Windows和Linux兩種版本下載。

gudab Enterprise滿足企業級MongoDB維運最重要的三大功能:監控、告警、備份,若您有其他考量,可以使用免費版的 gudab Express。
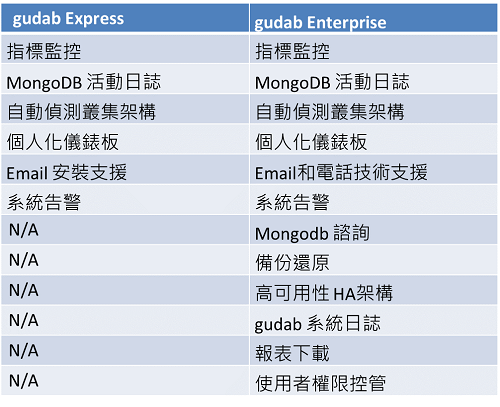
6大模組與特色
gudab提供企業環境所需之各種管理功能,包含系統監控、備份還原、儀表板、異常告警、活動與使用者管理等模組。

6大特色
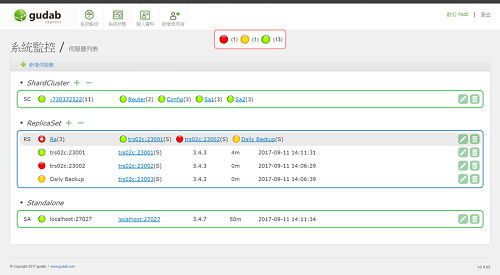
1. 叢集架構自動偵測
Auto-discovery 自動偵測並描繪系統拓樸,將所有叢集內MongoDB自動列出,並顯示主機型態與清單以便設定進行監控。若Replica Set或Sharded Cluster有多個成員時,無需一一輸入FULLNAME(host:port) 加入監控,只要輸入其中一員,就能把整個叢集相關成員加入監控。
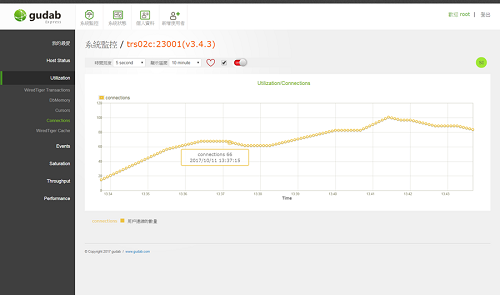
2. 指標監控
可針對CPU、RAM、Disk、Connection、Index、Throughput等超過30種以上指標進行監控,透過即時圖表,顯示系統狀況。MongoDB本身提供系統指令,查詢指標性能,而gudab 將其記錄下來,根據時間顆粒,做成時間序列圖呈現。
3. 系統告警
透過伺服器清單以及監控指標,管理者可個別針對伺服器設定所有監控指標之告警觸發動作,支援E-mail與SNMP等告警通知方式。並且gudab還提供用戶設定例外時間,讓資料庫在預期的時間下線,系統不會持續發信告警。相比常見的 Nagios、Cacti等監控工具,gudab提供UI操作,不用在小黑窗維護多組配置檔,只需要簡單的輸入然後click即可。

4. 系統活動日誌
記錄受監控之MongoDB Server的活動歷程,目前只有簡單的事項(開啟、關閉),gudab後續將完善此功能,以利稽核作業。

5. 個人化儀錶板
提供管理者針對監控指標,透過加入我的最愛方式,自行設定儀表板組合,以利日常監控管理工作(重點監控、截圖做成報表 …)。
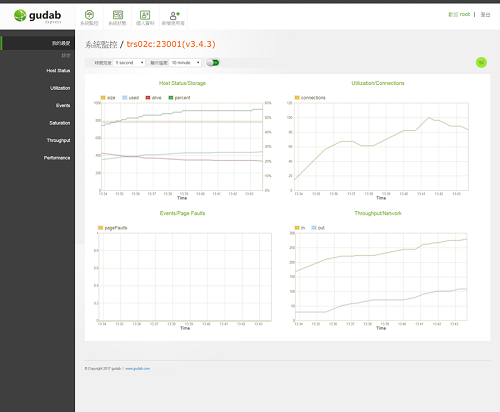
6. 備份還原
gudab是透過加入Delayed Secondary的方式,記錄一份1hr前(預設)的data files(全備),並另外記錄oplog(差異備份)。於人工全備還原後(copy-paste),中間差異的資料,可以透過gudab進行差異備份以及匯出與匯入還原,並可進階設定監控目標。

個案研究
實際案例
某企業影像流程系統採用 IBM FileNet,使用多年在資料大量累積,且流程邏輯日益複雜後面臨以下問題。經2017年導入新一代影像流程管理系統tribis後,有效解決問題,大幅增加營運效率。
問題
l FileNet 維護費用昂貴
l 系統效能日益惡化
l 原產品設計潛藏問題
n 流程與表單資料不同步
n 影像資料受限原產品編碼方式,無法直接查詢
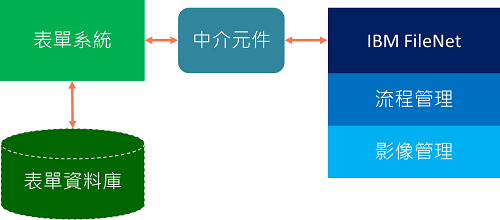
解決方案
以 MongoDB 取代 FileNet CE,無需改動表單系統和中介元件間的API。
1. 使用MongoDB 來管理保單影像檔資料,Binary檔案直接存進MongoDB中,並針對該檔案定義此檔案屬性描述(如受理編號),以便於快速搜尋檔案。
2. 應用系統透過MongoDB API 來存取保單影像資料,以Replica Set機制來提供資料備份與系統備援。
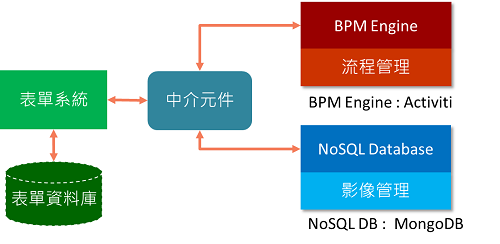
透過GridFS API 一次查詢,取得完整保單資料存到保單物件中 (屬性描述 + 實體檔案)。GridFS是MongoDB的一個規範,在存取大於16MB 的資料時,會寫入2個collections。

l 屬性描述:檔案名稱、檔案型態、檔案大小 …。
l 實體檔案:切分後的二進位資料,每筆以255kB為限。

硬體規格建議
巨量資料的建議架構
根據實務經驗,設計的考量如下:
l 雙中心備援架構
l 實現雙中心就近存取資料 (Data Center Awareness)
l 雙叢集系統
n 第一層系統放近期資料
n 第二層系統放歷史資料
l 最小編制至少12個 Data Node
n 第一層系統 Replication Factor = 3 (會有2份副本)
n 第二層系統 Replication Factor = 2 (會有1份副本)

依節點角色建議規格
l Data Node
泛指儲存實際資料的實例 standalone, primary, secondary,需裝在一定水準的 x86 Server(Eg. 12 physical cores, 256GB RAM)。建議裝在本機、不建議裝在 VM。建議採用本地儲存、而非共同儲存設備(如 SAN 或 NAS)。建議每個 Data Node 獨立一台 x86 Server(專屬機)。
l non- Data Node
泛指沒有儲存實際資料的實例 mongos, configsvr, arbiter,可裝在等級較低的 x86 Server 或 VM(Eg. 4 physical cores, 16GB RAM),建議 Mongos Server 與 AP Server 裝在同一台,數量視 AP Server 的數量決定。建議 Configsvr Server 獨立裝在等級較低的 x86 Server。建議 Arbiter Server 裝在 VM 上即可。
估算硬碟大小範例
l 經驗
通常影響 MongoDB 效能的資源因素是 RAM,故可從 RAM 大小來反推硬碟大小。若單台 x86 規格為 12 cores, 256GB RAM,標準案例能保證有效處理 2TB的資料量。
l 理由
至少需將 index 放入 RAM ,才能保證資料庫效能。通常 index size 為資料量的 10% (需視實際案例),故 256GB RAM 能支持 2.5TB 的資料量,通常會抓 20%緩衝,則實際支持的資料量為 2.5TB x 80% = 2TB。













